分布式数据库介绍
过去一段时间有研究分布式数据库,什么是分布式数据库呢?
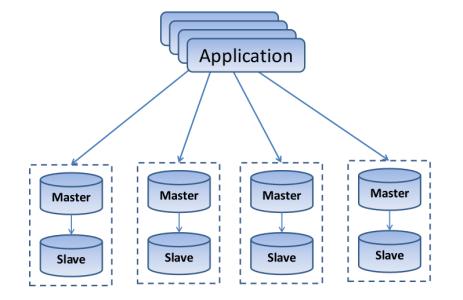
分布式数据库区别于常见的主从架构数据库集群,首先数据存储是分布式的,分开存储在多台服务器上,但数据访问服务还是跟集中式类似,一般都有统一的访问入口。
一般常见的 MySQL 主从集群,是先有一个主服务实例,写数据操作一般是通过这个主服务实例完成的,然后会有多个从服务实例,是从主服务实例自动同步数据过来,从服务实例可以对外提供数据查询服务,一般不用于写数据操作。
这种主从架构一个比较大的问题是在数据量很大的时候,在存储方面难以满足需要,比如每天写入100G的数据,这么多数据首先要有足够的硬盘空间,还要有足够的网络带宽用于主从服务间同步数据。一般一台服务器能配置的硬盘空间是有限的,不太可能做到无限扩容,只能考虑分布式存储技术,也就是通过增加服务器的方式使存储空间做到水平扩展。这种扩展是存储层面的,可以通过例如 Hadoop 这种大数据技术实现一种分布式文件系统,然后挂载到服务器上当作硬盘空间来使用。
而分布式数据库是从更高层面来解决上面的问题,数据是分开存放在多个服务实例上,这些服务实例可能使用普通的硬盘来存储数据,也可能使用分布式文件系统存储数据。比如有100条数据,有5个服务实例,可能每个服务实例保存了20条。这些服务实例也有机制来相互备份,通过多复本冗余存储的方式来做到数据高可用。
这种多服务实例需要解决协调调度的问题,比如写入数据时应该写到哪个服务实例上,读数据时怎样能读取到所有的数据,或者怎么知道某条数据是存在哪个服务实例上。所以一般分布式数据库系统都有个用于协调和调度资源的服务,它就是用来解决读写数据时的资源调度问题。
TiDB 介绍
我测试了 TiDB 这个分布式数据库系统,它的分布式存储层叫 TiKV,是一个基于 Key-Value 机制的分布式存储系统。它的资源调度服务叫作 PD,就是用于协调数据访问服务的,PD 会告诉你写数据时写到哪个 TiKV 实例上,读数据时要从哪个 TiKV 实例上读。
TiDB 比较牛的一方面是提供了一套兼容 MySQL 协议的关系数据库层,让你可以用 MySQL 的 SQL 语法来访问数据,这就大大提高了实用性,让很多已有的基于 MySQL 的应用系统可以很平滑的迁移过来。
我是用 TiDB 来保存 ESB 平台的 API 调用日志记录,每天经常高达100万条记录以上,以前用 MySQL 保存时因为数据都是保存在一台服务器上,硬盘空间很快就满了,总是扩容硬盘空间又不现实,所以用上 TiDB 就解决了分布式存储的问题,我们用3台服务器,每台分担1/3的存储空间,而且可以追加服务器,来进一步分散,减少单台服务器的存储空间要求。
在使用过程中,随着数据量越来越大,发现性能方面出现问题了,首先是查询数据时,因为单表记录数已经几亿级别了,每次查询都感觉比较慢,而且查询时 CPU 占用很高,导致数据写入方面也变慢,整体日志记录和查询服务的体验不太好。初步分析应该是在数据量到一定程度后,PD 分布式资源调度服务很繁忙,需要不断从各 TiKV 服务读取数据,比较容易导致服务器负荷增大。
轻量数据库解决方案
后来就思考其他解决方案,这种日志保存对数据一致性要求不高,主要是提供汇总数据,用于跟踪 ESB 平台的总体服务情况。我就考虑按每天一张表的方式来保存,查询时也按天,因为看到 TiDB 对 CPU 占用过高,就想用其他小型数据库来代替,存储方面最好能每天一个数据库文件,能压缩起来,方便移动到其他服务器上,解决分布式存储问题。
根据以前的使用经验,我选择了 HSQLDB,这个是兼容标准 SQL 语法的一种小型数据库,可以内嵌到应用系统里,可以以一个文件的方式保存一个数据库。我们就把每天的 API 调用记录保存到一个数据文件,并压缩来节约硬盘空间,随时可以转移到其他服务器上。实际测试这种方案效果很好,用单台服务器就能满足以前几台服务器才能做的工作,而且服务器 CPU 负荷很低,响应很快。
总结
总结一下上面的经历,个人感觉分布式数据库系统也并非是万能的,它们也有自己的弱点,估计需要很大的服务器资源投入才能保证较好的数据服务,比如 Hadoop 大数据平台,动辄需要几十台服务器的环境,资源投入很大。而对于一些非关键型的应用场景,一些简单的解决方案可能更适合,所以要根据实际需要选择恰当的解决方案。